Gemma 4 Benchmarks: How a 31B Model Competes with Giants 20× Its Size
A detailed look at Gemma 4's benchmark results — from Arena AI rankings to MMLU, AIME, LiveCodeBench, and vision scores. See how Google's open models stack up against competitors with 600B+ parameters.
When Google released Gemma 4 in early April 2026, the headline claim was bold: an open-weight model with just 31 billion parameters matching or beating models with 600 billion or more. That sounds like marketing. But the benchmark numbers — from independent leaderboards and standardized tests — actually back it up.
This article breaks down the performance data across reasoning, coding, vision, and more, so you can decide for yourself whether those numbers translate into real-world usefulness.
The Big Picture: Performance vs. Size
One chart from Google's Gemma 4 page tells the story better than any paragraph:
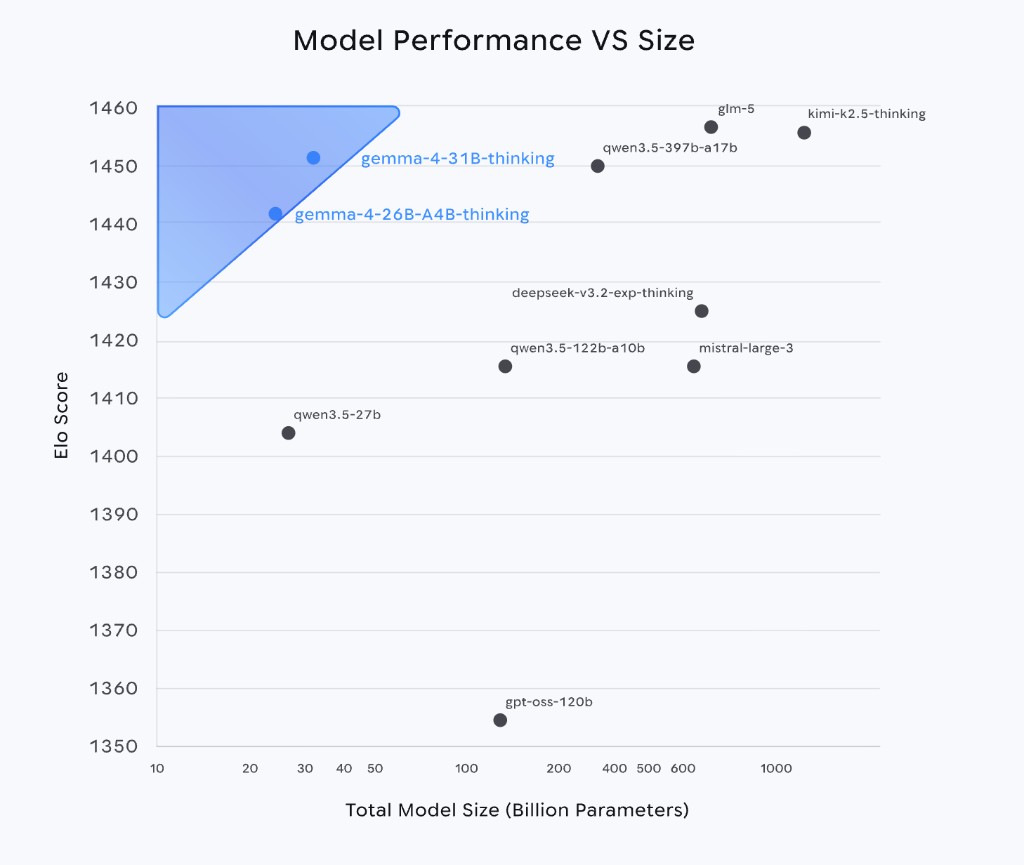
This scatter plot maps Elo score (vertical axis, higher is better) against total model size in billions of parameters (horizontal axis, log scale). The two blue dots in the upper-left corner are Gemma 4's 31B and 26B models.
What stands out: they're sitting at Elo scores above 1440, surrounded by models that are 10× to 30× larger — Qwen 3.5-397B, GLM-5, Kimi K2.5, all in the 600B–1000B range. Meanwhile, models of comparable size like Qwen 3.5-27B sit significantly lower on the chart.
That upper-left corner is exactly where you want to be: maximum performance, minimum size. It means you can run these models on hardware that would never handle a 600B model.
Where Gemma 4 Ranks: Arena AI Leaderboard
The Arena AI leaderboard ranks models through blind head-to-head comparisons voted on by real users — not automated tests. It's one of the most respected measures of practical model quality.
As of April 2026, Gemma 4's standings:
| Model | Elo Score |
|---|---|
| Gemma 4 31B (thinking) | 1452 |
| Gemma 4 26B A4B (thinking) | 1441 |
| Gemma 3 27B | 1365 |
For context, an Elo gap of 87 points between Gemma 4 31B and Gemma 3 27B is substantial — it represents a major generational leap in just one release cycle. The 26B MoE variant, despite activating only 3.8 billion parameters per token, scores just 11 points behind the full dense model.
Benchmark Deep Dive
Below are the official results from Google's Model Card, covering the instruction-tuned models with thinking enabled. We'll walk through each category.
Reasoning and Knowledge
These benchmarks test how well a model can think through complex problems.
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 3 27B |
|---|---|---|---|---|
| MMLU Pro (multilingual Q&A) | 85.2% | 82.6% | 69.4% | 67.6% |
| GPQA Diamond (expert-level science) | 84.3% | 82.3% | 58.6% | 42.4% |
| AIME 2026 (competition math) | 89.2% | 88.3% | 42.5% | 20.8% |
| BigBench Extra Hard | 74.4% | 64.8% | 33.1% | 19.3% |
A few things jump out:
AIME 2026 is a competition-level math benchmark — the kind of problems that trip up most humans. Gemma 4 31B scoring 89.2% is remarkable for any model, let alone a 31B open one. The 26B MoE is right behind at 88.3%, suggesting the MoE architecture loses very little reasoning quality.
GPQA Diamond tests PhD-level scientific reasoning. Gemma 4 nearly doubled Gemma 3's score (84.3% vs. 42.4%), which is one of the largest jumps across all benchmarks.
Coding
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 3 27B |
|---|---|---|---|---|
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 29.1% |
| Codeforces Elo | 2150 | 1718 | 940 | 110 |
LiveCodeBench v6 uses fresh competitive programming problems to avoid data contamination — the model can't have memorized these during training. Going from 29.1% (Gemma 3) to 80.0% (Gemma 4 31B) is a nearly 3× improvement.
Codeforces Elo of 2150 places the 31B model at a "Candidate Master" level on the competitive programming platform. For perspective, Gemma 3's Elo of 110 was essentially beginner-level. The 26B MoE at 1718 ("Expert" rank) is impressive for a model that only activates 3.8B parameters per token.
Vision
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 3 27B |
|---|---|---|---|---|
| MMMU Pro (multimodal reasoning) | 76.9% | 73.8% | 52.6% | 49.7% |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 46.0% |
| OmniDocBench 1.5 (edit distance ↓) | 0.131 | 0.149 | 0.181 | 0.365 |
MMMU Pro tests whether a model can reason about images — charts, diagrams, scientific figures — not just describe them. The 31B model scores 76.9%, a solid improvement over Gemma 3's 49.7%.
OmniDocBench measures document understanding accuracy (lower is better). Gemma 4 31B cut the error rate by nearly two-thirds compared to Gemma 3, which matters a lot for anyone using the model to parse invoices, receipts, or technical documents.
Agentic Tool Use
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 3 27B |
|---|---|---|---|---|
| τ2-bench (avg. over 3 domains) | 76.9% | 68.2% | 42.2% | 16.2% |
τ2-bench (tau-2) simulates real-world agent scenarios — retail, airlines, and more — where the model must use tools, look up information, and follow multi-step procedures. Gemma 3 was essentially unusable here at 16.2%. Gemma 4 31B at 76.9% suggests the model can actually function as a practical autonomous agent.
Long Context
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 3 27B |
|---|---|---|---|---|
| MRCR v2 8-needle 128K (avg.) | 66.4% | 44.1% | 25.4% | 13.5% |
This test plants 8 "needles" (specific facts) in a 128K-token document and asks the model to retrieve them. Gemma 4 31B at 66.4% shows it can handle long documents far better than Gemma 3, though there's still room for improvement — this remains one of the harder challenges for all models in this size class.
The Generational Leap: Gemma 4 vs. Gemma 3
To appreciate how much changed in one generation, here are the percentage-point improvements from Gemma 3 27B to Gemma 4 31B:
| Benchmark | Gemma 3 27B | Gemma 4 31B | Improvement |
|---|---|---|---|
| MMLU Pro | 67.6% | 85.2% | +17.6 pts |
| AIME 2026 | 20.8% | 89.2% | +68.4 pts |
| LiveCodeBench v6 | 29.1% | 80.0% | +50.9 pts |
| GPQA Diamond | 42.4% | 84.3% | +41.9 pts |
| MMMU Pro | 49.7% | 76.9% | +27.2 pts |
| τ2-bench | 16.2% | 76.9% | +60.7 pts |
These aren't incremental gains. The math, coding, and agentic benchmarks improved by 50–68 percentage points, which is closer to a complete generational shift than a typical version bump.
The 26B MoE: When Efficiency Meets Quality
The 26B A4B variant deserves its own spotlight. Here's the paradox it solves: it holds 26 billion total parameters but only activates about 3.8 billion per token. That means:
- It runs nearly as fast as a 4B model (fewer active parameters = fewer computations per token)
- It reasons nearly as well as the 31B dense model (88.3% vs. 89.2% on AIME, 82.6% vs. 85.2% on MMLU Pro)
- It needs less memory at runtime than the 31B (15.6 GB vs. 17.4 GB at Q4_0)
In the Performance vs. Size chart, the 26B sits in the same upper-left zone as the 31B — both far above models of comparable total size. For anyone trying to balance quality against hardware constraints, the 26B MoE is arguably the most practical model in the lineup.
Want to check if your hardware can handle these models? See our Hardware Requirements guide.
What These Benchmarks Mean in Practice
Benchmark scores are useful for comparison, but what do they actually mean when you're sitting in front of a terminal?
If you care about coding help — LiveCodeBench and Codeforces scores suggest Gemma 4 31B can handle real coding problems, not just textbook examples. The jump from Gemma 3's 29% to 80% on LiveCodeBench means it went from "occasionally helpful" to "reliably useful" for code generation.
If you need document analysis — The vision improvements (MMMU Pro, OmniDocBench) mean the model can actually read and reason about charts, tables, and scanned documents with reasonable accuracy. It's not perfect, but it's crossed the threshold into practical utility.
If you're building agents — The τ2-bench results are the most dramatic improvement. A model that scores 77% on real-world agentic tasks can be a foundation for automation workflows. At 16%, Gemma 3 couldn't.
If you want reasoning quality — GPQA Diamond and AIME scores approaching or exceeding 85% put Gemma 4 in territory that was reserved for API-only frontier models just a year ago. Running this level of reasoning locally, on your own hardware, is new.
A Note on Benchmark Limitations
No benchmark tells the full story. A few things worth keeping in mind:
- Arena AI scores fluctuate as new models enter and the user voting pool changes. The scores cited here are from early April 2026.
- Thinking mode matters. The numbers above are for instruction-tuned models with thinking enabled. Without thinking mode, scores will be lower, especially on math and reasoning tasks.
- Benchmarks don't measure personality, tone, or creativity — things that matter a lot in practice but are hard to score objectively.
- Data contamination is always a concern. LiveCodeBench v6 specifically uses fresh problems to mitigate this, but not all benchmarks take that precaution.
The best benchmark is always your own use case. These numbers tell you what's possible; only testing on your actual tasks tells you what's useful.
What's Next?
Ready to see these numbers in action on your own machine?
- Check your hardware first: Gemma 4 Hardware Requirements
- Get it running: Run Gemma 4 with Ollama
The gap between "frontier AI" and "stuff you can run on a Mac Mini" just got a lot smaller.